机器学习之正则化
本文共 566 字,大约阅读时间需要 1 分钟。
#Overfittion(过拟合)
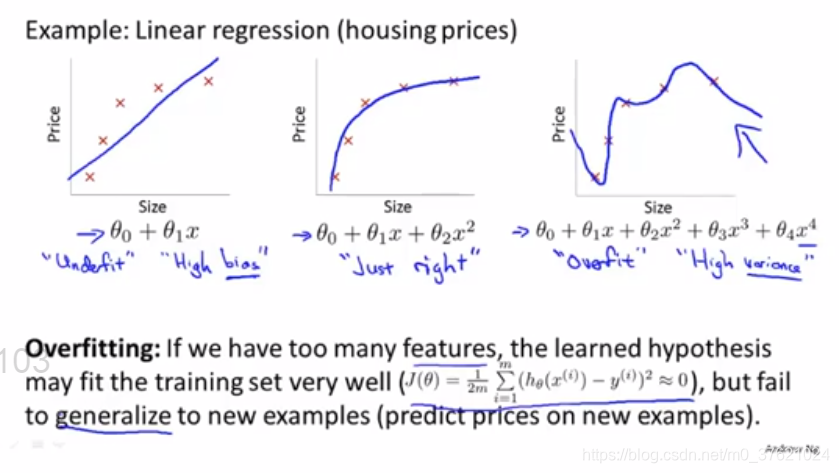
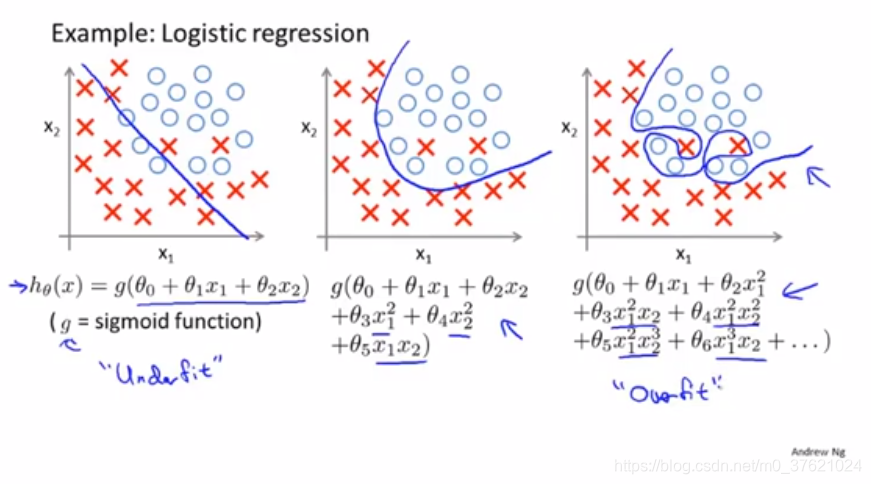
如果有过多的变量,而只有非常少的训练数据,就会出现过度拟合的问题。
#如何解决?
1、减少特征的数量
2、正则化

#Cost function(代价函数)
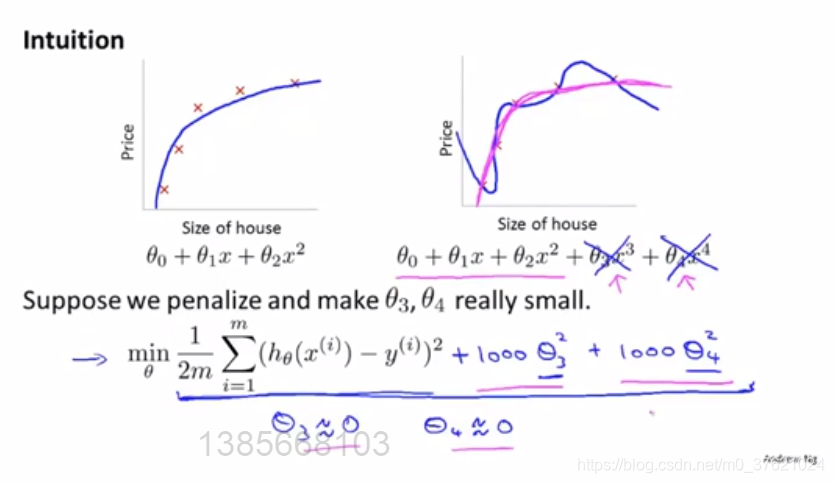
- penalize(加入惩罚项)
#正则化背后的思想:

修改代价函数,来缩小所有的参数(因为不知道该去缩小哪些参数)。即加一个额为的正则项,来缩小每个参数的值。
*约定俗成从1开始,而不是从0开始求和。
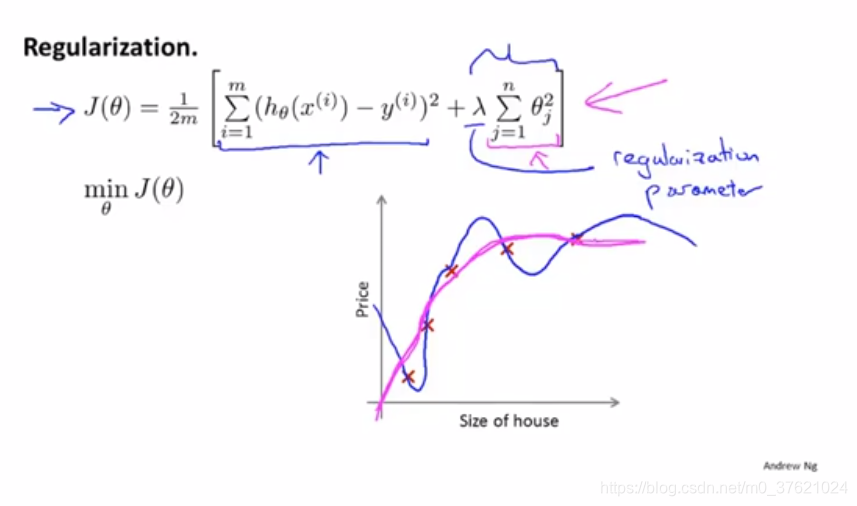
- regularization parameter(正则化参数λ)
- λ的作用是控制两个不同目标之间的取舍。第一个目标与目标函数的第一项有关(即我们想去训练的),第二个目标是我们要保持参数尽量得小,与正则化目标有关。
#Regularized linear regression(线性回归的正则化)
方法一)对代价函数J(θ)进行梯度下降:

每次迭代的时候,都将θj乘以一个比1略小的数,即每次都把参数缩小一点,然后进行和之前一样的更新操作。
方法二)用正则方程来解决
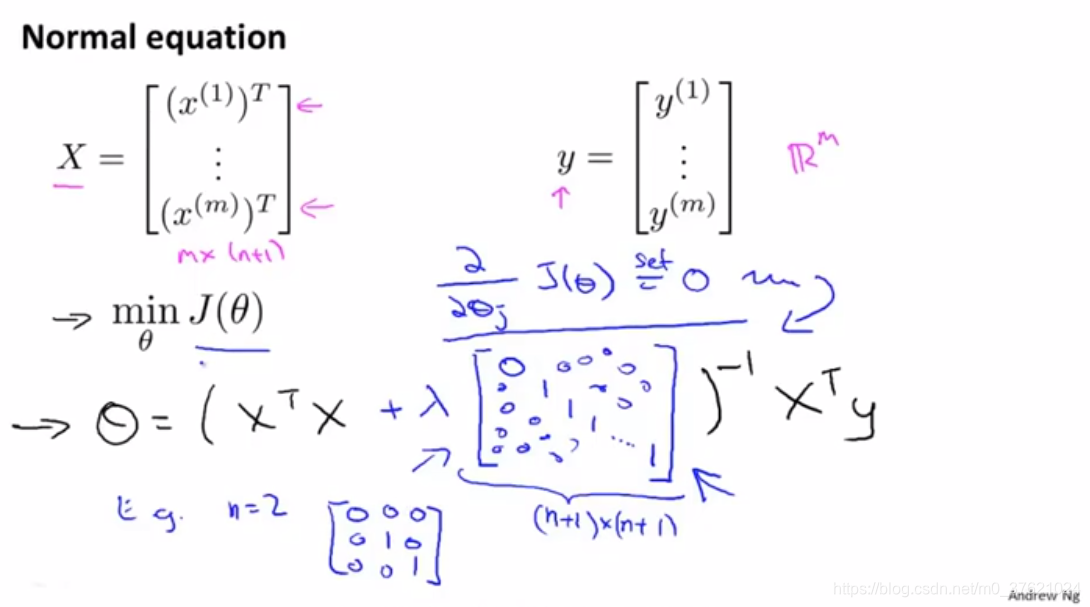
*补充:如果样本数量比特征数量少,那么X'X不可逆。

所以,进行正则化还可以解决一些X'X出现不可逆的问题。
#Regularized logistic regression(逻辑回归的正则化)

正则化逻辑回归的梯度下降算法:

PS.内容为学习吴恩达老师机器学习的笔记【】
转载地址:http://npqn.baihongyu.com/
你可能感兴趣的文章